联通手机信令大数据的处理分析与可视化
本文共 4273 字,大约阅读时间需要 14 分钟。
我有联通的2020年扩样后的具体迁徙人数数据,包括所有城市
如果需要的话请到我其他文章找到我的qq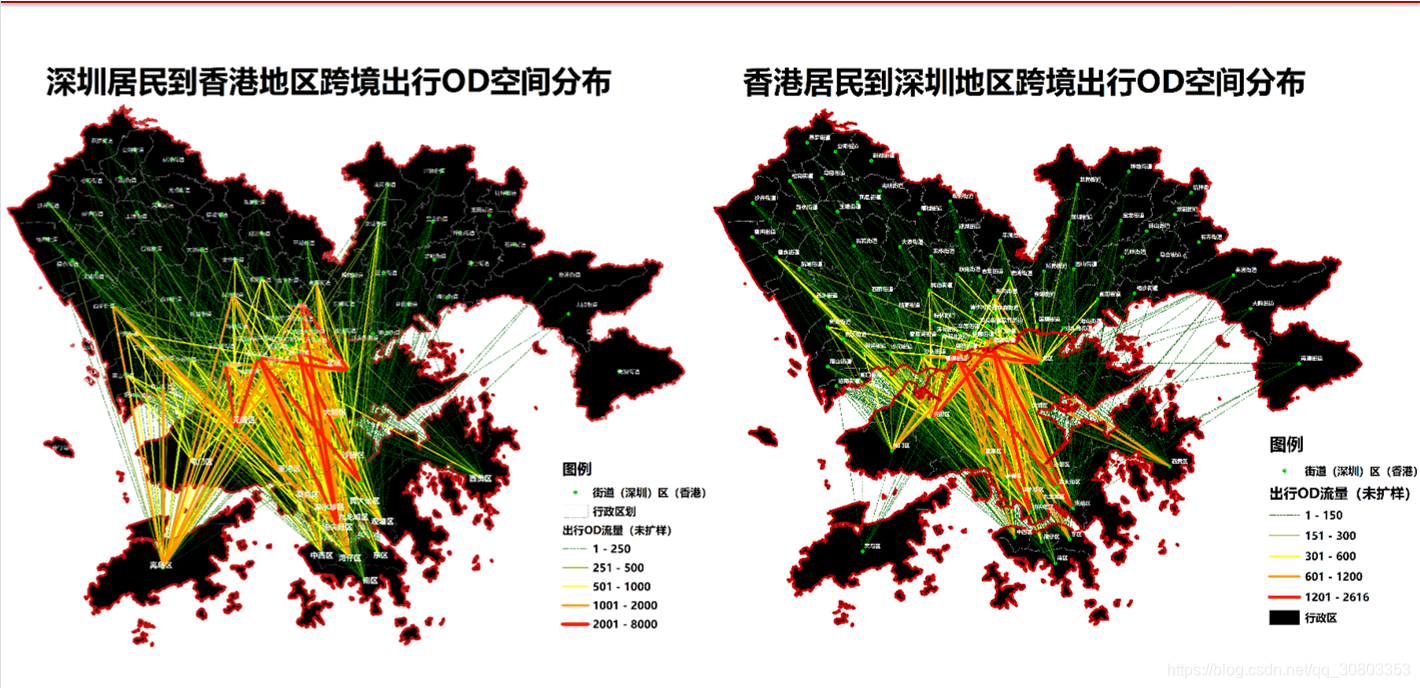
数据处理代码:
import pandas as pdimport osfrom utils.read_write import eachFile, pdReadCsv'''每个社区到达商圈的平均人口数, #3代表节假日#2代表周末 #1代表工作日 * START_GRID_ID 起始网格编号 string * START_CITY 起始城市 string * END_GRID_ID 到达网格编号 string * END_CITY 到达城市 string * date 日期 string * START_TYPE 起始人口类型 string 01-到访 02-居住 03-工作 05职住重合 * END_TYPE 到达人口类型 string 01-到访 02-居住 03-工作 * POP 人数 int * times 次数'''# def test():# filepath = os.path.join(root+'000054_0_weekend.txt')# data = pd.read_csv(filepath, sep='|', usecols=[0, 2, 4, 7], error_bad_lines=False, engine='python')# column = ['START_GRID_ID', 'END_GRID_ID', 'date', 'pop']# data.columns = column# # data = data[data['date'].isin([20191013])]# workFromCom = pd.merge(data, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right')# workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right')# workGroup = workFromComToMall.groupby(['SQCODE', 'mall_name']).agg({'pop': sum})# csv = workGroup['pop'].apply(lambda x: int(x / 5))# csv.to_csv(filepath + 'holidayFromCommunityToMall.csv', mode='a')def read_file(dirpath): filepath = os.path.join(dirpath) print(dirpath) data = pd.read_csv(filepath, sep='|', usecols=[0, 2, 4, 7], error_bad_lines=False, engine='python') column = ['START_GRID_ID', 'END_GRID_ID', 'date', 'pop'] data.columns = column weekend = data[data['date'] == 20191013] workFromCom = pd.merge(weekend, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right') workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right') workGroup = workFromComToMall.groupby([ 'SQCODE', 'mall_name']).agg({ 'pop': sum}) csv = workGroup['pop'].apply(lambda x: int(x / 5)) csv.to_csv(save + 'weekendFromCommunityToMall.csv', mode='a',header=False,index=True) holiday = data[data['date'] < 20191008] workFromCom = pd.merge(holiday, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right') workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right') workGroup = workFromComToMall.groupby([ 'SQCODE', 'mall_name']).agg({ 'pop': sum}) csv = workGroup['pop'].apply(lambda x: int(x / 5)) csv.to_csv(save + 'holidayFromCommunityToMall.csv', mode='a',header=False,index=True) work = data[(data['date'] > 20191007) & (data['date'] != 20191013)] workFromCom = pd.merge(work, community, left_on='START_GRID_ID', right_on='YGA_Grid_1', how='right') workFromComToMall = pd.merge(workFromCom, mall, left_on='END_GRID_ID', right_on='YGA_Grid_1', how='right') workGroup = workFromComToMall.groupby([ 'SQCODE', 'mall_name']).agg({ 'pop': sum}) csv = workGroup['pop'].apply(lambda x: int(x / 5)) csv.to_csv(save + 'workFromCommunityToMall.csv', mode='a',header=False,index=True)def groupby(): src = 'D:\学习文件\项目文件\规土委\data\od\save\save\\' data = pd.read_csv(src+'workFromCommunityToMall.csv',sep=',',names=['SQCODE','mall_name','pop']) group = data.groupby(['SQCODE','mall_name']).agg({ 'pop':sum}) csv = group['pop'].apply(lambda x: int(x / 6)) csv.to_csv(src+'workCommunityToMall'+'.csv',header=True) data = pd.read_csv(src+'holidayFromCommunityToMall.csv',sep=',',names=['SQCODE','mall_name','pop']) group = data.groupby(['SQCODE','mall_name']).agg({ 'pop':sum}) csv = group['pop'].apply(lambda x: int(x / 7)) csv.to_csv(src+'holidayCommunityToMall'+'.csv',header=True) data = pd.read_csv(src+'weekendFromCommunityToMall.csv',sep=',',names=['SQCODE','mall_name','pop']) group = data.groupby(['SQCODE','mall_name']).agg({ 'pop':sum}) group.to_csv(src+'weekendCommunityToMall'+'.csv',header=True)if __name__ == '__main__': groupby() root = 'D:\学习文件\项目文件\规土委\data\od\other\\' save = 'D:\学习文件\项目文件\规土委\data\od\comTomall\\' grid = 'D:\学习文件\项目文件\规土委\data\od\YGA\\' community_file = 'com_grid.txt' community = pdReadCsv(grid + community_file, sep=',') mall = pd.read_csv(grid + 'mall_grid.txt', sep=',', dtype=str) # test() for dir in eachFile(root): # read_file(root + '000054_0_unholiday') read_file(root + dir) 转载地址:http://jugdf.baihongyu.com/
你可能感兴趣的文章
【成长之路】本科比赛作品设计经验分享
查看>>
Qt设置QTextEdit和QLabel的字体颜色
查看>>
Qt phonon多媒体框架
查看>>
linux下Mplayer安装与设置指南(以及如何加载显示中文字幕)
查看>>
Qt多媒体播放phonon
查看>>
Mysql group by 详解
查看>>
Qt学习笔记
查看>>
Qt主题风格设置
查看>>
android问题汇总-待解决
查看>>
sql数据库语句问题及总结
查看>>
sql数据库触发器
查看>>
Could not reserve enough space
查看>>
2020-09-27 优秀的毕业生 罗升阳
查看>>
定时器ScheduledExecutorService与Timer
查看>>
DatePicker之timeInMillis must be between the values of getMinDate() and getMaxDate()解决
查看>>
【原文翻译】Android应用程序集成SQLCipher实现SQLite加密
查看>>
Duplicate class com.xxx.xxx found in modules问题解决(aidl相互依赖问题)
查看>>
AndroidStudio Gradle依赖管理 - 不包括传递依赖exclude(一)
查看>>
Android Studio代码迁移问题小汇总
查看>>
weightSum与layout_weight属性使用
查看>>